

Feed via Date Primer Tutorial
Feeds, as Wikipedia reminds us …
Data feed is a mechanism for users to receive updated data from data sources. It is commonly used by real-time applications in point-to-point settings as well as on the World Wide Web. The latter is also called web feed.
… are a big part of a lot of people’s habits in the online world. As a data updating mechanism, feeds and dates go hand in hand. The users of feed URLs (yes, a feed can be boiled down to a URL, in its essence) are interested in the freshness of its data, as defined, normally, by the URL of the feed involving some reference to a date of interest. Syncing of data on modern mobile devices is just like importing feed data for a date that is now, and updating files and databases accordingly.
Today we take the starting steps on a project that looks at this “feed URL construction” as a generic exercise allowing for …
- single date (equating in your thinking, perhaps, to “data on” or “data since” or “data before” or “data of”) … or …
- two dates (equating to “data between” or “data outside of” and/or perhaps the ideas of above)
In today’s “single feed snapshot” progress in this, we concentrate on …
- piecing together a feed URL from its constituent parts …
- prefix to first date
- first date, optionally
- optional URL bits between first date and second date
- optional second date
… and …
- optional hashtag consisting of an emailee to send the feed data report to
The form of our feed is a web feed, as the data remains as HTML that can be linked to and/or be contained in an email attachment. Within that HTML web data, in many scenarios, a user interested in a particular form of data will reduce a larger amount of web data into a smaller amount of other more formal forms of data, such as CSV data for spreadsheets, or JSON data for hierarchical data, as two such “data feed” (type) examples. Occasionally you will hear of the term web scraping to describe this concept. We allow for the user to link back to the PHP web application, within an email link, so they can create their own “single feed snapshot” for themselves.
Of course, there are great proprietry feed tools out there, as you can read about with the previous FeedBurner Web Feed Primer Tutorial but to start thinking about your own feed system can be both an interesting exercise and a good private data sharing arrangement with a trusted business partner, perhaps. In this sense, we encourage you to try the live run “first draft” version with underlying PHP feed_via_date.php code.
Previous relevant FeedBurner Web Feed Primer Tutorial is shown below.
FeedBurner Web Feed Primer Tutorial
We’ve opened a FeedBurner web feed management provider account for the Robert James Metcalfe Blog, our WordPress 4.1.1 blog at this link. Let’s see what Wikipedia says about FeedBurner, which Google acquired on 3rd June 2007, here and below …
FeedBurner is a web feed management provider launched in 2004.[1] FeedBurner was founded by Dick Costolo, Eric Lunt, Steve Olechowski, and Matt Shobe. Costolo is a University of Michigan graduate, and was CEO of Twitter from 2010 to 2015. FeedBurner provides custom RSS feeds and management tools to bloggers, podcasters, and other web-based content publishers.
Web feed management providers like FeedBurner are pretty important to bloggers because a lot of web traffic to blogs these days does not come from the user finding the blog news via their favourites or out of habit each day, but rather from “feeds” they have subscribed to, that they use the precis headline of to decide whether they want to read further on a topic of interest or disgust or whatever or what…everrrrrr.
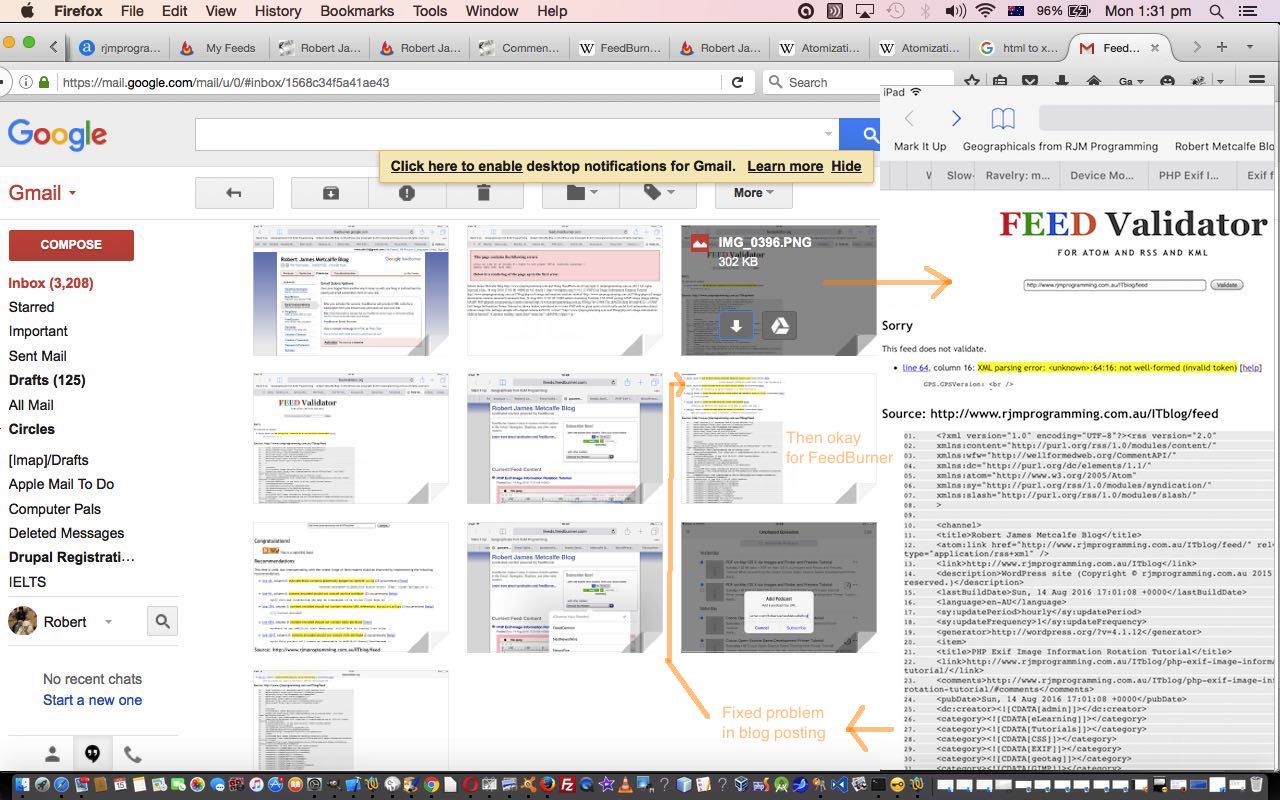
It was fairly straightforward as a Google Gmail user to sign up for the Robert James Metcalfe Blog feed to be registered with FeedBurner. More or less just follow your nose with a visit to HTTP://feedburner.com … but what was a bit surprising was the next day’s realization that just because some content looks okay in HTML it would necessarily be totally okay for FeedBurner which requires that content to validate in terms of XML data as well.
Now here is where the FeedBurner “Troubleshootize” tab functionalities called (for the Robert James Metcalfe Blog feed) …
… can come into their own to show you any potential problems.
If this was interesting you may be interested in this too.
If this was interesting you may be interested in this too.

